GPT-1 모델 설명

Introduction
GPT는 2018년에 OpenAI 에서 발표한 Improving Language Understanding by Generative Pre-Training 논문에서 발표한 언어 생성 모델이다. 사실 오늘날 GPT는 모르는 사람이 없을정도로 유명한 모델이자 LLM의 대명사가 되어버렸다. GPT 논문에서 가장 중요하게 다루는 개념은 제목에도 나와 있듯 “Pretraining” 일 것이다. NLP 분야에서 label이 있는 데이터는 그렇지 않은 데이터에 비해 절대적인 수가 압도적으로 부족하다. 따라서 unlabel된 데이터로 pretraining하여 미리 represent를 배우고, 차후에 label이 있는 데이터로 fine-tuning을 한다면 필요한 task에서 사용할 수 있게 된다.
Relative Work
- Semi-supervised Learning for NLP : label이 없는 데이터로 학습된 word embedding을 활용해 텍스트 분류 등의 task의 성능을 향상 시켰습니다. 하지만 해당 방법으로는 단어 수준에서 관계는 포착했지만 더 높은 level에서의 의미를 파악하지 못했습니다.
- Unsupervised pre-training : 비지도 데이터를 통해 모델의 좋은 초기 파라미터를 찾는 과정으로, 지도학습 전에 일반화를 도와줌
- Auxiliary training objectives : 보조 학습 목표란 주 목표 외에도 다른 추가적은 태스크를 함께 학습하여, 모델이 더 좋은 표현을 학습하도록 돕는 방식이다. 이때 충분한 Unsupervised pre-training를 진행한다면 이것 없이도 언어적 특성이 충분히 학습되어 해당 효과가 줄어들 수 도 있다고 한다.
Framework
Unsupervised pre-training
학습 목표
\[L_1(\mathcal{U}) = \sum_{i} \log P(u_i \mid u_{i-k}, \ldots, u_{i-1}; \Theta)\]- $\mathcal{U} = {u_1, …, u_n}$ : 라벨이 없는 토큰 시퀀스(corpus)
- k : 컨텍스트 윈도우의 크기, 즉 $u_i$를 예측할 때 사용할 때 이전 k개의 토큰을 사용한다.
- $\Theta$ : 학습할 파라미터
해당 수식은 비지도 학습 상황에서 모델이 이전 단어를 보고 다음 단어를 예측할 수 있도록 하는 것이다. 이때 확률값을 곱하는 것 대신 로그를 취해 다 더하는 방식으로 log-likelihood를 구하고 이를 극대화하는 것이 목표이다. 여기서 SGD를 통해 Backpropagation을 통해 학습을 진행한다.
학습 과정
\[\begin{aligned} h_0 &= U W_e + W_p \\ h_l &= \text{transformer\_block}(h_{l-1}) \quad \forall i \in [1, n] \\ P(u) &= \text{softmax}(h_n W_e^T) \end{aligned}\]첫번째 수식
- $U$ : 컨택스트 토큰 백터들의 모음, 예를 들자면 최근 k개의 토큰을 모은 집합
- $W_e$ : 토큰 임베딩 행렬
- $W_p$ : 포지셔널 인코딩 행렬 첫번째 수식에서는 초기 임베딩 벡터를 계산한다. 직관적으로 트랜스포머에 넣기 전에 임베딩 벡터와 포지셔널 인코딩을 해주는 것으로 보면된다. 트랜스포머에서 임베딩 행렬의 행을 가져오는 것과 달리 word2vec에서 처럼 U는 원핫 인코딩을하고 임베딩행렬을 곱해주는 방식을 사용한다. 실제 구현에서는 트랜스포머처럼 lookup방식을 사용할 수도 있다.
두번째 수식
- $h_{l-1}$ : 이전 층의 출력
- transformer_block : 이는 하나의 트랜스포머 블록으로, Multi-head attention, FFN, Add & Norm 과정을 포함
- n : 트랜스포머 블록의 총 갯수를 의미 해당 수식은 여러 트랜스포머 블록을 차례대로 통과하면서 $h_0$부터 $h_n$까지 점차 고수준의 표현을 학습해나간다.
세번째 수식
- $h_n$ : 마지막 트랜스포머 블록의 출력
- $W_e^T$ : 토큰 임베딩의 전치행렬로, 마지막 층의 표현을 토큰 벡터공간으로 투영시키기 위해 사용 최종 출력을 이용하여 모델이 다음 등장할 확률 분포를 softmax함수를 통해 계산한다. 이때 입력된 컨택스트 기반으로 다음 토큰을 예상하는 것이다.
Model Architecture
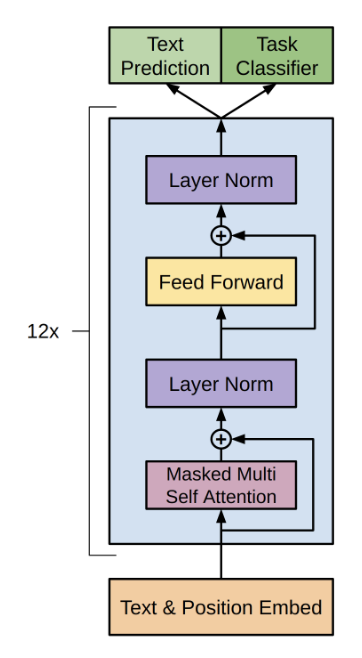
GPT의 구조는 트랜스포머의 디코더만을 사용한 형태이며, 다음과 같이 총 12개의 디코더 블록을 쌓는 방식으로 구성된다.
Supervised fine-tuning
\[P(y \mid x^1, \dots, x^m) = \text{softmax}(h_l^m W_y).\]- $y$ : 라벨
- $x^1, \dots, x^m$ : 입력 토큰들의 수식
- $h_l^m$ : pretrain된 트랜스포머의 최종 벡터표현
- $W_y$ : 선형 변환을 위한 행렬
트랜스포머 모델로 처리된 최종 벡터표현 $h_l^m$에 대해 $W_y$로 선형변환을 진행한 후 softmax를 취해 출력될 확률을 계산한다. 이 때 $x^1, \dots, x^m$ 가 입력되었을 때 y가 출력될 확률을 계산하는 것이다.
\[L_2(C) = \sum_{(x,y)} \log P(y \mid x^1, \dots, x^m).\]- $C$ : 라벨이 포함된 데이터셋, $y$ 과 $x^1, \dots, x^m$ 로 구성되어 있음
이는 지도학습단계에서 log-likelihood를 계산하는 것이며, 이를 목적함수로 한다.
\[L_3(C) = L_2(C) + \lambda \ast L_1(C)\]- $L_1$ : 비지도학습에서의 log likelihood
- $L_2$ : 지도학습에서의 log likelihood
- $\lambda$ : 비지도학습의 기여도를 조절하는 하이퍼 파라미터
다음은 auxiliary objective로 모델의 최종 손실함수로서 이용한다. $L_3$는 최종 학습의 목표로 지도학습과 비지도학습의 모델링 목표를 가중합한 형태이다. 이를 최대화 하는게 목표이지만 실제 구현상에서는 negative형태로 하여 손실함수로 쓸 수 있다. 이를 통해 모델이 지도학습으로부터 학습하면서 동시에, 비지도 언어 모델링을 통해 언어의 일반적 특성도 잘 학습할 수 있도록 하는 것이다.
Task-specific input transformations
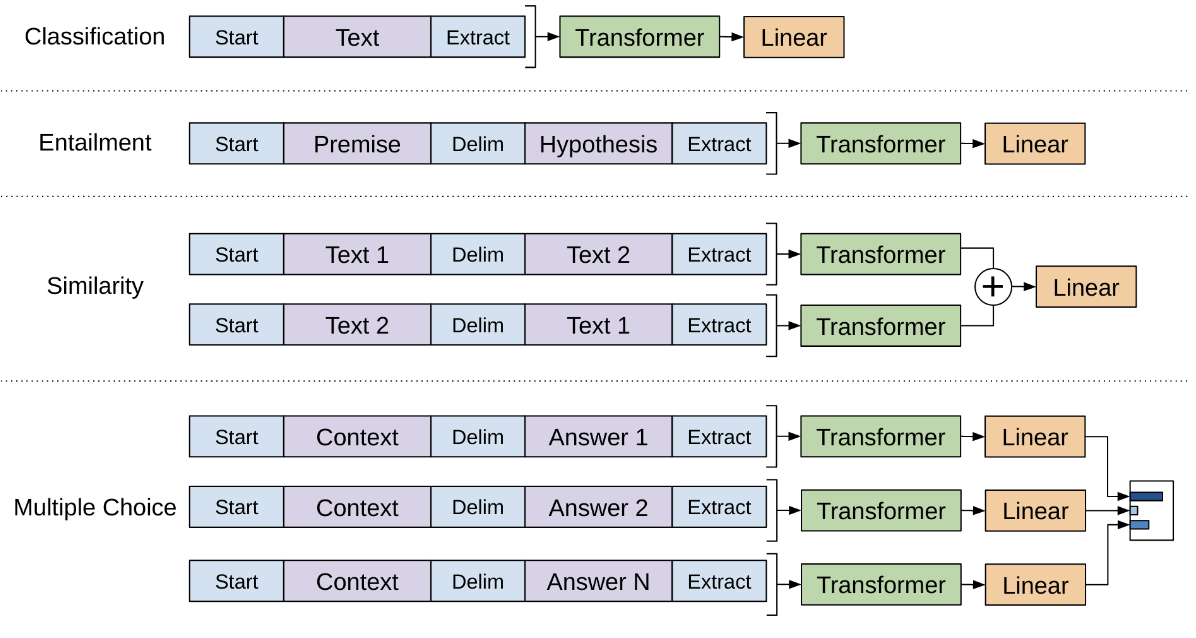
그렇다면 Fine Tuning단계에서 input data는 어떻게 구성하는 것일까? 수행하려는 task에 맞는 input data를 구성해야할 것이다. 그래서 GPT-1은 총 4가지 Task에 대한 Input data 구성 방법을 제안한다.
1. Classification
해당 task는 입력되는 문장이 어떤 범주에 속하는지를 분류하는 것이다. 가장 단편적인 예시로 스팸 여부를 분류하는 문제가 있을 것이다.
- 변환 방법 : $\langle s \rangle\; \text{Text}\; \langle e \rangle$
$\langle s \rangle\;$는 start 토큰, $\langle e \rangle\;$는 end 토큰 혹은 extract 토큰을 의미함. 논문 본문과 figure에서 다른 표현을 사용하고 있지만 같은 의미로 사용한다. 트랜스포머의 출력을 linear+softmax에 넣어 해당 문장이 어떤 class에 속하는지 분류한다.
2. Textual Entailment
해당 task는 premise(전제)와 hypothesis(가설)로 구성된 두 문장이 주어졌을 때, 두 문장 사이의 관계가 참(entailment), 거짓(contradiction), 중립(neutral) 중 어떤 것인지를 판별 하는 것.
- 변환 방법 : $\langle s \rangle\; \text{Premise}\; \text{Delim}\; \text{Hypothesis}\; \langle e \rangle$
$는 Delim으로 구분자의 역할로 쓰이고 있다. 깃허브 수식상 달러기호가 적히지 않아 Delim이라는 키워드로 작성하였다. 위 classification과 마찬가지로 트랜스포머의 출력을 linear + softmax 에 넣어 결과를 분류한다.
3. Similarity
해당 task는 두 문장 사이의 유사도를 계산하는 task이다.
- 변환 방법
- (1) $\langle s \rangle\; \text{Text1}\; \text{Delim}\; \text{Text2}\; \langle e \rangle$
- (2) $\langle s \rangle\; \text{Text2}\; \text{Delim}\; \text{Text3}\; \langle e \rangle$
위의 두 task와 다르게 두 문장을 양방향으로 트랜스포머에 입력한다. 각각의 시퀀스의 출력 벡터를 element-wise addition한 후 Linear을 통해 최종 유사도를 계산한다. 당연하겠지만 유사도이므로 분류가 아닌 회귀 문제로 해당 task에서는 softmax를 취하진 않는다.
4. Question Answering and Commonsense Reasoning
다음은 Q&A 혹은 상식 추론을 하는 task 이다. 해당 task의 경우 여러 답변이 나올 수 있다. 따라서 질문과 여러 답변에 대한 출력 벡터들을 각각 계산해야한다.
- 변환 방법 : $\langle s \rangle\; \text{Context}\; \text{Delim}\; \text{Answer}_k\; \langle e \rangle$
각각의 답에 대해 맞을 확률을 계산하고, 마지막에 softmax를 취해 후보중에 하나를 최종적으로 선택한다.