GoogleNet(Inception) 모델 설명 with pytorch

이미지 넷 모델 리뷰
Introduction
GoogleNet은 2014년 ILSVRC(ImageNet Large Scale Visual Recognition Challenge)에서 우승한 모델로 Inception 모듈을 처음으로 제시한 모델이다. 이는 차후에 여러 기법들이 적용되면서 inceptionv4까지 점점 다양한 모델이 나오게 된 토대가 됐다. 해당 모델을 통해 AlexNet보다는 더 깊지만 파라미터는 더 적다는 특징을 갖고 있다.
해당 모델은 독창적인 구조를 통해서 적은 파라미터 수와 정확도에서 좋은 성능을 보였지만, 구현의 어려움으로 인해 VGGNet보다는 덜 활용되는 네트워크이기도 하다.(이는 VGGNet이 image recognition에 더 좋다는 평이 많기 때문이기도 하다)
Background
그 당시 딥러닝 모델을 향상 시키는 방법으로 생각되는 방법은 layer의 depth을 좀 더 깊게 만들거나, width를 증가시키는 방법이 있다. 여기서 width를 증가 시킨다는건 채널(노드)을 증가시킨다는 것을 의미합니다. 즉 해당 방법을 통해 모델의 파라미터를 증가시키는게 모델의 성능을 증가시키는 방법인 것이다.
하지만 단순하게 파라미터를 증가시키는 것에는 문제가 있다. 첫번째는 overfitting이 발생하기 쉬워진다는 점. 그리고 두번째로는 학습과정과 추론 과정에서 컴퓨팅 리소스를 많이 사용하게 된다는 점이다. 그리고 vanishing gradient problem 또한 발생할 수 있었기에 단순하게 파라미터를 증가시킬순 없었다.
GoogleNet에 대해 이해하기 위해선 Network in Network 논문에서 제안한 1x1 Conv 연산을 알고 있어야한다. 1x1 Conv layer를 통해 채널의 크기를 변경할 수 있고, 네트워크의 크기를 제한할 수 있다. 이를 통해 계산량을 제한하면서 width를 증가할 수 있게 된다.
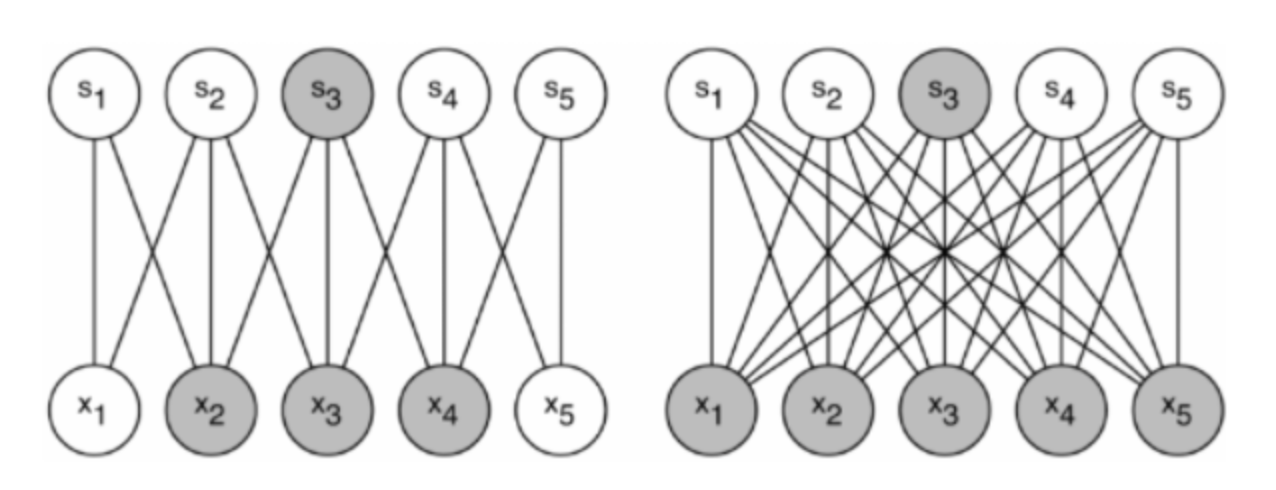
overfitting 문제와 많은 연산량이 필요한 문제를 해결하기 위해서는 fully connected 구조에서 sparse(희소)한 구조로 바꾸는 것이 더 효율적이라는 것을 주장한다. 기존의 연구를 통해 내부적으로 희소한 연결구조를 가진다면, 즉 필요한 것끼리만 연결된 희소한 구조라면 데이터의 분포를 효율적으로 나타낼 수 있다는 것을 말한다. 그렇기에 출력이 유사한 뉴런끼리, 즉 같은 기능을 하는 뉴런끼리를 그룹화하여 실질적인 연결구조를 만든 다면, 최적의 토폴로지 구조를 얻을 수 있게 된다. 위 사진에서 왼쪽이 Sparse한 구조, 오른쪽이 Dense한 fully connected 구조이다.
근데 gpu를 통한 병렬 컴퓨팅을 하기 위해서, 그리고 딥러닝 프레임워크에서는 완전 연결방식을 사용해야 한다.(정확히는 그렇게 하지 않으면 비효율적이다) 그렇기에 희소연결 구조를 사용하면서도 dense한 방식으로 처리할 수 있는 아키텍처에 대해 고민하게 된다.
Inception Module
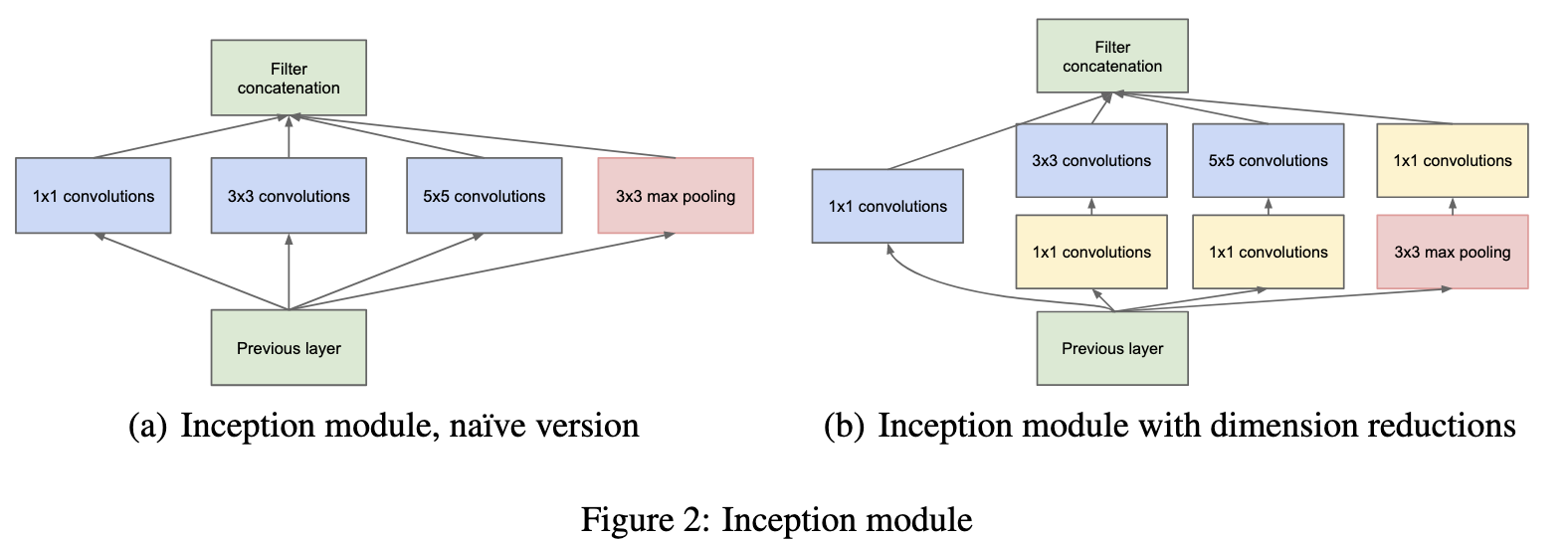
그래서 여기서 제안되는 것이 inception 모듈이다. 기존의 CNN에는 수많은 필터를 하나의 레이어에 집어넣어 알아서 학습되는 방식을 선택하였다. 하지만 위 Inception 모듈을 보면 4가지 갈래로, 즉 다른 역할을 하는 필터끼리 묶고 필요없는 연결은 줄이는 방식을 선택한 것이다.
기존에는 한 레이어에 동일한 필터를 사용했다. 그런데 여기서 동일한 필터를 사용하는게 최선일까? 그렇지 않다. 어떤 feature는 작은 영역(1x1, 3x3)에서 잘 들어날 것이며, 어떤 특징은 큰 영역(5x5)에서 잘 들어날 것이다. 따라서 한 레이어에서 모든 뉴런을 동일하게 연결하는 것이 아닌 필요한 부분끼리 묶어서 서브네트워크로 최적화하는 것이다. 위 inception module을 보면 1x1, 3x3, 5x5 Conv연산을 병렬적으로 수행하는 것을 알 수 있다. 또한 pooling을 진행했을 때 성능이 좋다는게 이미 입증되었기에 추가적인 효과를 위해 pooling연산도 적용하였다.
그런데 3x3과 5x5 Conv연산의 경우 망이 깊어짐에 spatial concentration 이 감소될 것으로 예상 되기 때문에 따라 필터의 채널의 수는 증가한다. 즉 깊은 레이어일 수록 더 넓은 범위를 보고 중요한 정보만 남겨, 공간적인 정보는 감소하고, 개념적인 정보는 증가하게 된다. 그렇기에 더 다양한 정보(패턴)을 익히기 위해 채널을 늘려 전체적인 표현력을 늘리려고 노력하는 것이다.
근데 그 뜻은 곧 파라미터가 늘어나니 연산량이 증가한다는 것이다. 그래서 여기서 1x1 Conv 연산을 통해서 채널의 차원을 축소한다. 이를 통해 3x3과 5x5의 입력 채널수가 감소하여 연산량이 줄어들 수 있고, non-linearity를 추가할 수 있다. 또한 1x1은 채널간의 weight sum으로 볼 수 있으므로 채널간의 관계를 학습할 수 있다. 그리고 Pooling브랜치 뒤에도 1x1연산을 적용하여 채널 수를 최적화 해준다.
GoogleNet Architecture
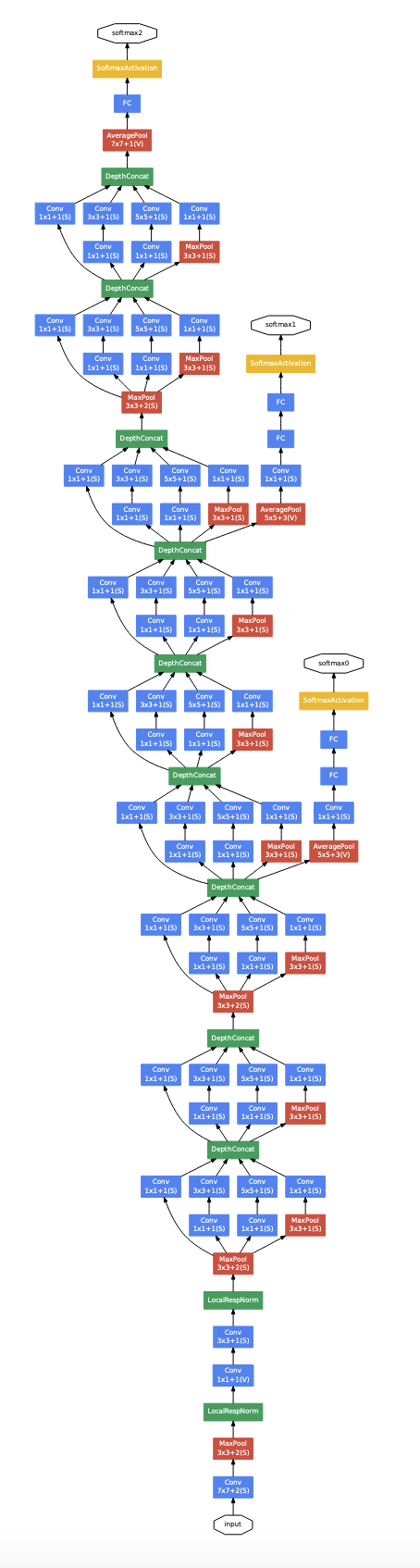
이는 GoogleNet의 전체 아키텍처이다. 논문의 한페이지를 아키텍처를 어떻게 구성했는지로 꽉채워놓았다. 좀 무식해보이긴 하지만 가장 직관적으로 어떤식으로 모델을 구성했는지 쉽게 알 수 있다. 중요한 부분만 알아보자
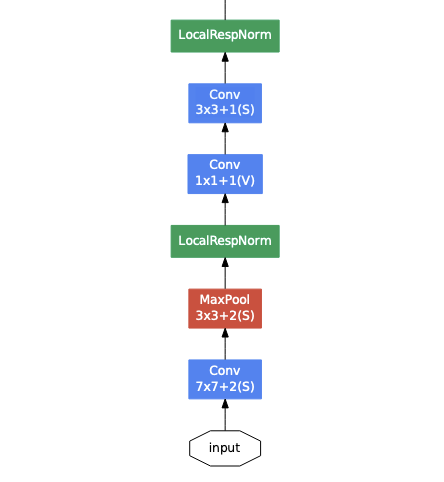
먼저 초반 레이어 부분에서는 일반적인 7x7과 3x3 Con 레이어를 사용한다. 이는 학습과정에서 효율적인 메모리 사용을 위해서 이렇게 구성했고, 깊은 레이어에서 Inception Module을 사용한다. 또한 LocalRespNorm, 즉 LRN(Local Response Normalization)를 사용하는데, 이는 AlexNet에서 사용한 것과 같은 nomalization 기법이다.
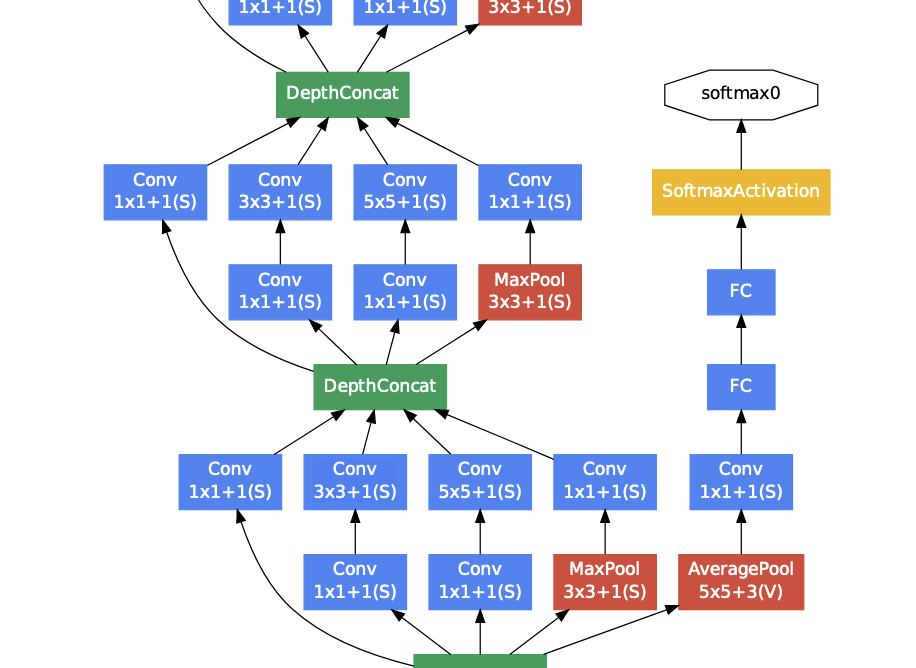
다음은 Inception Module을 사용하는 파트이다. 위에서 설명한 inception module을 그대로 사용하는 것을 볼 수 있다.
여기서 눈여겨봐야할 점은 중 auxiliary classifier가 적용되어있다는 것이다.(해당 아키텍처에는 총 2개가 적용되어있다.) 모델이 깊어질 경우 vanishing gradient problem이 발생할 수 있는데 이를 해결하기 위한 방법으로 쓰이고 있다. 레이어 중간중간에서 auxiliary class(보조 분류기)를 두어 중간에서 추가적인 역전파를 발생시켜 gradient가 초반 레이어까지 잘 전달 될 수 있도록 하고 정규화 효과를 볼 수 있도록 하였다. 이때 loss에 0.3을 곱하여 보조분류기가 너무 큰 영향을 주는 것을 방지하였고, 테스트단계에서는 제거하였다고 한다.
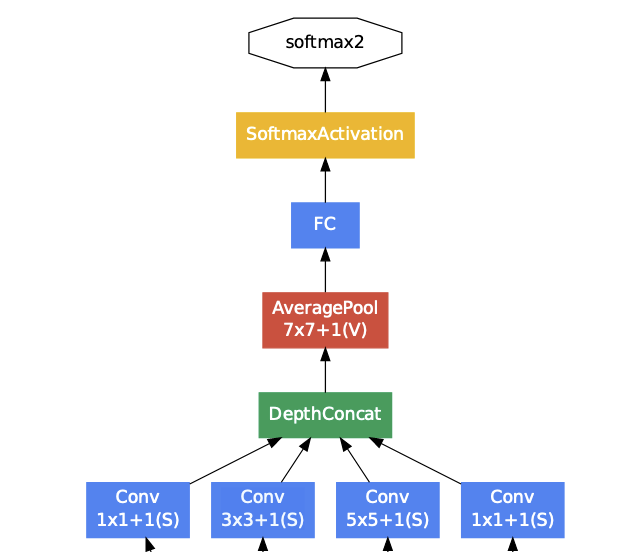
그리고 마지막에 결과가 전달 될때는 Global Average Pooling을 적용하여, 채널들별 평균을 하나의 벡터로 만들어 FC레이어를 통해 최종 분류를 하게된다. 이는 파라미터의 감소효과와 overfitting를 방지하려는 목적을 가지고 있다.
GoogleNet 코드 리뷰
class BasicConv2d(nn.Module):
def __init__(self, in_channels: int, out_channels: int, **kwargs: Any) -> None:
super().__init__()
self.conv = nn.Conv2d(in_channels, out_channels, bias=False, **kwargs)
self.bn = nn.BatchNorm2d(out_channels, eps=0.001)
def forward(self, x: Tensor) -> Tensor:
x = self.conv(x)
x = self.bn(x)
return F.relu(x, inplace=True)
torchvision에 구현된 GoogleNet 코드를 확인해보자. 코드의 이해를 위해 구현 된 코드에서 순서는 바뀌어서 가져왔다. 다음 클래스는 Conv2d에 배치정규화와 ReLU가 적용된 클래스로 보면 된다.
또한 F.relu부분의 inplace=True옵션을 사용할경우 파이토치에서 변수의 메모리를 직접 바꾼다고 한다. 원래 파이토치에서 연산을 하면 새로운 변수에 값이 저장되지만, 이렇게 하면 기존 변수의 값이 변경되어 속도나 메모리에서 이점이 있지만 backpropagation과정에서 조금 문제가 생길 수 있다고 한다.
Inception 모듈
class Inception(nn.Module):
def __init__(
self,
in_channels: int,
ch1x1: int,
ch3x3red: int,
ch3x3: int,
ch5x5red: int,
ch5x5: int,
pool_proj: int,
conv_block: Optional[Callable[..., nn.Module]] = None,
) -> None:
super().__init__()
if conv_block is None:
conv_block = BasicConv2d
self.branch1 = conv_block(in_channels, ch1x1, kernel_size=1)
self.branch2 = nn.Sequential(
conv_block(in_channels, ch3x3red, kernel_size=1), conv_block(ch3x3red, ch3x3, kernel_size=3, padding=1)
)
self.branch3 = nn.Sequential(
conv_block(in_channels, ch5x5red, kernel_size=1),
# Here, kernel_size=3 instead of kernel_size=5 is a known bug.
# Please see https://github.com/pytorch/vision/issues/906 for details.
conv_block(ch5x5red, ch5x5, kernel_size=3, padding=1),
)
self.branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1, ceil_mode=True),
conv_block(in_channels, pool_proj, kernel_size=1),
)
def _forward(self, x: Tensor) -> List[Tensor]:
branch1 = self.branch1(x)
branch2 = self.branch2(x)
branch3 = self.branch3(x)
branch4 = self.branch4(x)
outputs = [branch1, branch2, branch3, branch4]
return outputs
def forward(self, x: Tensor) -> Tensor:
outputs = self._forward(x)
return torch.cat(outputs, 1)
다음으로 볼 모듈은 GoogleNet의 핵심인 인셉션 모듈이다. 인자가 조금 많긴한데 패턴이 반복되고 있다.인자들을 다음과 같이 요약해볼 수 있다.
in_channels: 해당 모듈에 입력 되는 채널 수chNxN: NxN의 출력 채널 수chNxNred: NxN의 필터의 입력, 즉 1x1 Conv의 출력(여기서 red는 채널이 줄었다 하여 reduce의 의미로 쓰임)pool_proj: MaxPooling한 후 만들 1x1 Conv의 출력
그리고 branch로 총 4개로 나눠서 진행되는데, 위에서 본 Inception 모듈의 형태를 그대로 가져간다.
branch1: 1x1 Convbranch2: 1x1 Conv $\rightarrow$ 3x3 Convbranch3: 1x1 Conv $\rightarrow$ 5x5 Conv(실제론 3x3)- 여기선 3x3으로 구현되어 있음, 이는 텐서플로우에서 포팅된 모델이고 5x5를 3x3으로 대체해서 재학습시켜도 더 좋아진다는 보장이 없기때문에 그대로 둔다고 주석의 이슈에 적혀있음.
branch4: MaxPooling $\rightarrow$ 1x1 Conv
그리고 _forward를 통해 해당 branch들을 각각 forward 시킨 후, 해당 값을 concat하여 return해주게 된다.
InceptionAux 모듈 (보조 분류기, Auxilary Classifier)
class InceptionAux(nn.Module):
def __init__(
self,
in_channels: int,
num_classes: int,
conv_block: Optional[Callable[..., nn.Module]] = None,
dropout: float = 0.7,
) -> None:
super().__init__()
if conv_block is None:
conv_block = BasicConv2d
self.conv = conv_block(in_channels, 128, kernel_size=1)
self.fc1 = nn.Linear(2048, 1024)
self.fc2 = nn.Linear(1024, num_classes)
self.dropout = nn.Dropout(p=dropout)
def forward(self, x: Tensor) -> Tensor:
# aux1: N x 512 x 14 x 14, aux2: N x 528 x 14 x 14
x = F.adaptive_avg_pool2d(x, (4, 4))
# aux1: N x 512 x 4 x 4, aux2: N x 528 x 4 x 4
x = self.conv(x)
# N x 128 x 4 x 4
x = torch.flatten(x, 1)
# N x 2048
x = F.relu(self.fc1(x), inplace=True)
# N x 1024
x = self.dropout(x)
# N x 1024
x = self.fc2(x)
# N x 1000 (num_classes)
return x
해당 모듈은 GoogleNet의 보조 분류기가 구현된 것이다. 이는 구글넷의 학습을 원할하게 하기 위해, 중간레이어에서 추가적인 출력을 만들어서 예측을 한다. 해당 예측을 통해서 역전파를 도와주는 역할을 한다.
여기서 눈 여겨봐야할점은 해당 보조분류기가 2번의 fc레이어 뒤에 그대로 값을 출력한다는 것이다. GoogleNet 아키텍처를 보면 마지막에 softmaxActivation이 없다는 점이다. 해당 부분에 대해 의문이 들어 찾아보니 criterion으로 nn.CrossEntropyLoss()에 softmax가 포함되어있기 때문이라고 한다. 참고로 nn.BCELoss()는 softmax가 포함이 안되어있다고 하니, 해당 모델을 학습시킬때는 softmax를 포함시킨 코드로 학습을 시켜줘야 된다.
GoogleNet 코드
class GoogLeNet(nn.Module):
__constants__ = ["aux_logits", "transform_input"]
def __init__(
self,
num_classes: int = 1000,
aux_logits: bool = True,
transform_input: bool = False,
init_weights: Optional[bool] = None,
blocks: Optional[List[Callable[..., nn.Module]]] = None,
dropout: float = 0.2,
dropout_aux: float = 0.7,
) -> None:
super().__init__()
_log_api_usage_once(self)
if blocks is None:
blocks = [BasicConv2d, Inception, InceptionAux]
if init_weights is None:
warnings.warn(
"The default weight initialization of GoogleNet will be changed in future releases of "
"torchvision. If you wish to keep the old behavior (which leads to long initialization times"
" due to scipy/scipy#11299), please set init_weights=True.",
FutureWarning,
)
init_weights = True
if len(blocks) != 3:
raise ValueError(f"blocks length should be 3 instead of {len(blocks)}")
conv_block = blocks[0]
inception_block = blocks[1]
inception_aux_block = blocks[2]
self.aux_logits = aux_logits
self.transform_input = transform_input
self.conv1 = conv_block(3, 64, kernel_size=7, stride=2, padding=3)
self.maxpool1 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.conv2 = conv_block(64, 64, kernel_size=1)
self.conv3 = conv_block(64, 192, kernel_size=3, padding=1)
self.maxpool2 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception3a = inception_block(192, 64, 96, 128, 16, 32, 32)
self.inception3b = inception_block(256, 128, 128, 192, 32, 96, 64)
self.maxpool3 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception4a = inception_block(480, 192, 96, 208, 16, 48, 64)
self.inception4b = inception_block(512, 160, 112, 224, 24, 64, 64)
self.inception4c = inception_block(512, 128, 128, 256, 24, 64, 64)
self.inception4d = inception_block(512, 112, 144, 288, 32, 64, 64)
self.inception4e = inception_block(528, 256, 160, 320, 32, 128, 128)
self.maxpool4 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.inception5a = inception_block(832, 256, 160, 320, 32, 128, 128)
self.inception5b = inception_block(832, 384, 192, 384, 48, 128, 128)
if aux_logits:
self.aux1 = inception_aux_block(512, num_classes, dropout=dropout_aux)
self.aux2 = inception_aux_block(528, num_classes, dropout=dropout_aux)
else:
self.aux1 = None # type: ignore[assignment]
self.aux2 = None # type: ignore[assignment]
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.dropout = nn.Dropout(p=dropout)
self.fc = nn.Linear(1024, num_classes)
if init_weights:
for m in self.modules():
if isinstance(m, nn.Conv2d) or isinstance(m, nn.Linear):
torch.nn.init.trunc_normal_(m.weight, mean=0.0, std=0.01, a=-2, b=2)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def _transform_input(self, x: Tensor) -> Tensor:
if self.transform_input:
x_ch0 = torch.unsqueeze(x[:, 0], 1) * (0.229 / 0.5) + (0.485 - 0.5) / 0.5
x_ch1 = torch.unsqueeze(x[:, 1], 1) * (0.224 / 0.5) + (0.456 - 0.5) / 0.5
x_ch2 = torch.unsqueeze(x[:, 2], 1) * (0.225 / 0.5) + (0.406 - 0.5) / 0.5
x = torch.cat((x_ch0, x_ch1, x_ch2), 1)
return x
def _forward(self, x: Tensor) -> Tuple[Tensor, Optional[Tensor], Optional[Tensor]]:
# N x 3 x 224 x 224
x = self.conv1(x)
# N x 64 x 112 x 112
x = self.maxpool1(x)
# N x 64 x 56 x 56
x = self.conv2(x)
# N x 64 x 56 x 56
x = self.conv3(x)
# N x 192 x 56 x 56
x = self.maxpool2(x)
# N x 192 x 28 x 28
x = self.inception3a(x)
# N x 256 x 28 x 28
x = self.inception3b(x)
# N x 480 x 28 x 28
x = self.maxpool3(x)
# N x 480 x 14 x 14
x = self.inception4a(x)
# N x 512 x 14 x 14
aux1: Optional[Tensor] = None
if self.aux1 is not None:
if self.training:
aux1 = self.aux1(x)
x = self.inception4b(x)
# N x 512 x 14 x 14
x = self.inception4c(x)
# N x 512 x 14 x 14
x = self.inception4d(x)
# N x 528 x 14 x 14
aux2: Optional[Tensor] = None
if self.aux2 is not None:
if self.training:
aux2 = self.aux2(x)
x = self.inception4e(x)
# N x 832 x 14 x 14
x = self.maxpool4(x)
# N x 832 x 7 x 7
x = self.inception5a(x)
# N x 832 x 7 x 7
x = self.inception5b(x)
# N x 1024 x 7 x 7
x = self.avgpool(x)
# N x 1024 x 1 x 1
x = torch.flatten(x, 1)
# N x 1024
x = self.dropout(x)
x = self.fc(x)
# N x 1000 (num_classes)
return x, aux2, aux1
@torch.jit.unused
def eager_outputs(self, x: Tensor, aux2: Tensor, aux1: Optional[Tensor]) -> GoogLeNetOutputs:
if self.training and self.aux_logits:
return _GoogLeNetOutputs(x, aux2, aux1)
else:
return x # type: ignore[return-value]
def forward(self, x: Tensor) -> GoogLeNetOutputs:
x = self._transform_input(x)
x, aux2, aux1 = self._forward(x)
aux_defined = self.training and self.aux_logits
if torch.jit.is_scripting():
if not aux_defined:
warnings.warn("Scripted GoogleNet always returns GoogleNetOutputs Tuple")
return GoogLeNetOutputs(x, aux2, aux1)
else:
return self.eager_outputs(x, aux2, aux1)
이제 진짜 GoogleNet 코드를 보자. 대부분의 코드는 Inception과 InceptionAux모듈쪽에서 알아봤기에 쉽게 이해할 수 있다. 전에 본 alexnet과 vggnet을 비교할 때 차이가 있는 부분은 보조분류기와 jit의 사용여부가 될것이다.
우선 보조분류기의 경우, aux_logits변수가 True일때만 보조분류기를 사용하여 추가적인 출력을 만들어낸다. 이를 통해 학습단계에서 train이 좀더 잘 진행될 수 있도록 돕는다. 추론 단계에서는 필요가 없으므로 forward부분에서 self.trainging=True일때만 aux를 출력해주게된다.
그리고 eager_outputs메소드와 jit에 대해 알아보자. JIT는 Just-In-Time으로 torch.jit에 구현되어 있고, 모델이 일반적인 실행을 할때와 TorchScript모드에서 다르게 사용하기 위한 코드가 적혀 있다. eager_outputs메소드를 보면 일반적인 상태(Eager mode)일때 어떻게 데이터를 출력할지를 다루고 있다. 해당 메소드에서는 보조분류기 혹은 train(혹은 inference) 여부에 따라 출력을 바꿔주는 역할을 한다.
그렇다면 jit를 사용하는 경우는 총 2곳에서 나온다. 처음으로 위의 eager_outputs위의 데코레이터로 @torch.jit.unused라 되어 있는데, 해당 부분은 jit를 사용할 때 실행이 되어있지 않는다는 것이다. 다음으로 forward의 torch.jit.is_scripting()부분을 보면 되는데 해당 부분에서는 Torchscript를 통해서 실행되고 있을 때와 그렇지 않을때를 분리해서 진행이 된다. 해당 경우에서는 반환값이 무조건 일정하게 강제하는 것이다.