CLIP 모델 설명

Introduction
2021년에 OpenAI에서 발표한 2개의 논문이 있습니다. 하나는 CLIP이고 하나는 DALL-E입니다. DALL-E가 텍스트로 이미지를 만들어주는 모델이라면, CLIP은 zero-shot으로 이미지를 텍스트로 예측해주는 모델입니다. 특히 해당 모델은 새로운 데이터셋이나 태스크에 fine-tuning없이도 정확하게 예측할 수 있는 것을 목표로 만들어진 모델입니다. 멀티모달의 패러다임을 바꾸게 해준 논문으로 많이 소개 되는데 CLIP에 대해 알아보도록 합시다.
Background
우선 CLIP이 나오기 전에 있었던 문제점에 대해서 이야기 해봅시다. 기존에는 거대한 데이터셋을 통해 먼저 모델을 pre-train시킨 후, downstream task에 활용할 수 있도록 학습된 모델을 fine-tuning 시켰습니다.
이때 첫번째로 fine-tuning 없이는 새로운 downstream task에 활용할 수 없다는 점이었습니다.
두번째는 fine-tuning 과정에서는 많은양의 레이블이 추가로 필요했고, 이를 위해 많은 인력과 비용이 필요했습니다.
그리고 학습시킬 때 사용한 벤치마크 데이터셋은 현실 세계에서 수집한 성능과의 차이가 있어 모델의 성능이 떨어질 수 있다는 문제가 있었습니다.
그래서 OpenAI는 Pre-train만으로도 downstream task에서 좋은 성능을 내며, 이미지 수집 및 레이블링에 적은 노력이 들며, 현실 데이터셋에서도 좋은 성능을 보이는 모델을 만들고자 하였습니다. 그리고 그 모델이 바로 CLIP(Contrastive Language-Image Pre-training)입니다.
Approach
Natural Language Supervision
기존의 이미지 분류 모델에서는 고정된 크기의 클래스만 예측이 가능했습니다. 예를들면 이미지넷으로 학습시킨 모델은 1000개의 클래스만 인식하고, 그 이외의 개념을 인식하지 못했습니다.
하지만 CLIP에서는 자연어를 통해 이미지를 학습시킵니다. 단순하게 ‘cat’와 같이 학습시키는게 아닌 ‘A cute kitten playing with a ball’와 같이 텍스트를 통해 이미지의 개념을 학습시킬 수 있습니다. 이를 통해 zero-shot learning이 가능하게 됩니다.
Creating a Sufficiently Large Dataset
CLIP은 기존의 (이미지, 레이블) 방식이 아닌 (이미지, 텍스트)의 형식으로 데이터를 학습합니다. 이때 단순히 형식만 바뀌는게 아닌 웹에서 수집한 4억개의 데이터인 WebImageText를 이용합니다. 기존의 이미지넷 데이터셋이 1400만개였던 것과 비교하면 훨씬 많은 양의 데이터임을 알 수 있습니다.
해당 데이터들은 웹에서 뉴스, 블로그, SNS와 같은 다양한 도메인에서 수집됩니다. 클래스는 50만개이며, 이미지의 balance를 위해서 한 검색어당 최대 2만개의 이미지로 학습되었다고 합니다.
Contrastive Learning
CLIP에서는 contrastive learning을 사용하여 이미지와 텍스트간의 관계를 학습합니다. 일반적으로 contrastive learning에서는 같은 클래스의 데이터끼리는 유사도가 높게, 다른 클래스의 데이터끼리는 유사도가 낮게 되도록 학습이 진행됩니다.
이때 기존의 contrastive learning의 경우 이미지 쌍과 같이 같은 유형의 데이터를 비교하여 유사도를 계산하였지만, CLIP에서는 이미지 임베딩과 텍스트 임베딩간의 유사도를 통해 contrastive learning을 진행하게 된다.
Method
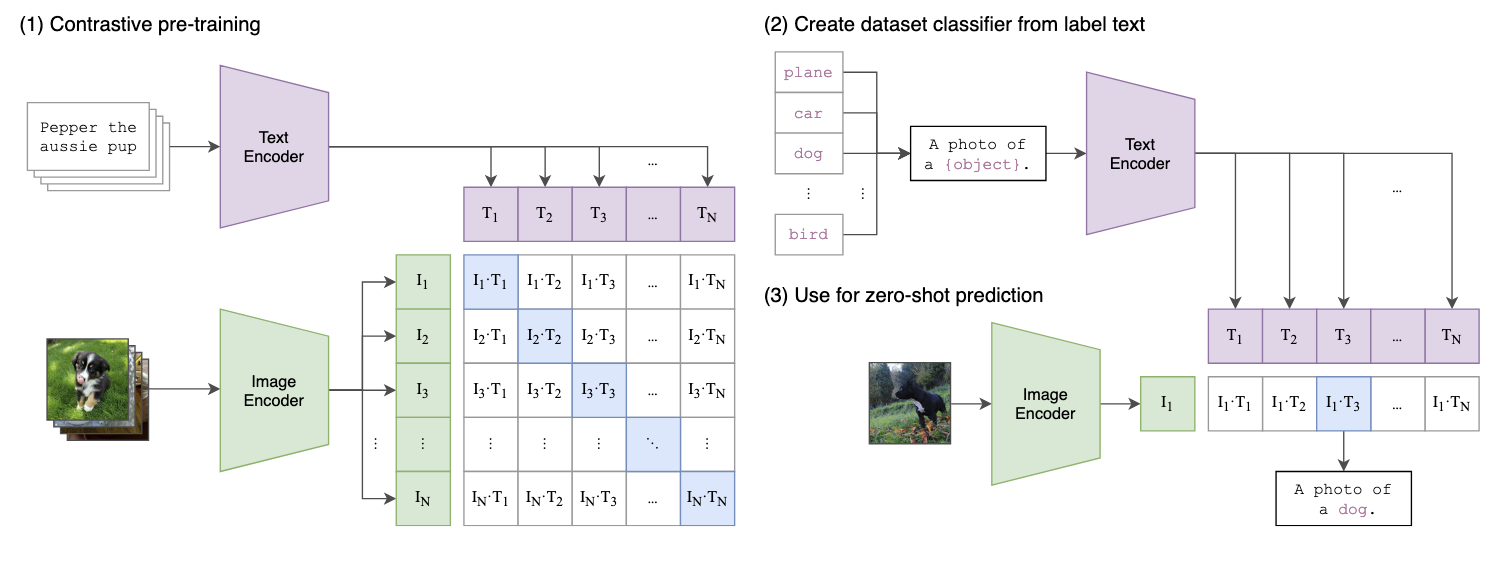
CLIP의 전체적인 프레임워크를 설명하는 figure입니다. CLIP을 처음 볼 때 가장 직관적으로 이해할 수 있습니다. CLIP은 다음과 같이 총 3단계로 이루어집니다. 차근차근 확인해봅시다.
1. Contrastive pre-training
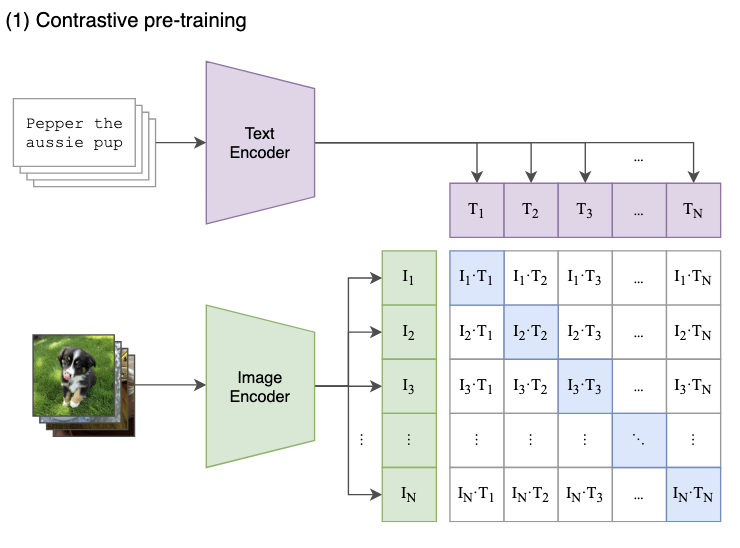

다음 이미지는 CLIP의 Contrastive pre-training에 대해 설명하고 있습니다. CLIP은 텍스트와 이미지를 각각 인코딩합니다. 이때 텍스트는 ResNet 혹은 ViT를 통해 인코딩하고, 텍스트 인코더로는 CBOW 또는 Transformer를 이용하였습니다. 그리고 이를 배치단위로 임베딩 벡터를 구하게 됩니다.
그렇게되면 배치크기가 N일때 이미지에 대한 벡터 $I_1 \dots I_N$과 텍스트에 대한 벡터 $T_1 \dots T_N$을 만들어 이를 정사위 figure와 가티이 정사각 행렬로 만듭니다. 실제로 사각행렬을 만든다기보다 비교하며 이해하기위해 다음과 같이 표현했다 보면 됩니다. 그러면 대각선에 있는 성분끼리는 같은 (이미지, 텍스트) 쌍이 될 것이고 나머지는 일치하지 않는 이미지 쌍이 될 것입니다. 즉 $I_n \cdot T_n$ 일때는 일치하는 pair 그 외에는 일치하지 않는 pair인 것입니다.
이를 바탕으로 consine similarity가 최소화 되도록 학습합니다. 학습하는 방법은 오른쪽 figure를 보면 이해할 수 있습니다. 우선 제일먼저 이미지와 텍스트를 각각에 맞는 feature extractor를 통해 feature를 먼저 추출합니다.($I_f, T_f$). 그 후 임베딩 행렬($W_i, W_t$)을 통해 해당 feature들을 같은 차원으로 만들어줍니다. 이는 기존의 인코더들은 단일 모달리티에 최적화 되어있어 고유의 임베딩 차원이 있는데, 이를 학습가능한 임베딩 행렬을 통해 한번 더 변환시켜주는 겁니다.
\[S_{ij} = \frac{I_e^i \cdot T_e^j}{\|I_e^i\| \|T_e^j\|} \cdot \exp(t)\]그다음 다음과같이 임베딩된 두 벡터를 내적하고, temperatue를 곱해 consine similarity를 계산합니다.
\[\begin{gather} L_i = -\frac{1}{N} \sum_{i=1}^N \log \frac{\exp(S_{ii})}{\sum_{j=1}^N \exp(S_{ij})} \\ L_t = -\frac{1}{N} \sum_{j=1}^N \log \frac{\exp(S_{jj})}{\sum_{i=1}^N \exp(S_{ij})} \end{gather}\]다음은 이미지와 텍스트 에서의 손실을 계산합니다. $L_i$는 이미지에서 텍스트 예측 손실(Image-to-Text Loss)를 의미하며, $L_t$는 텍스트에서 이미지 예측 손실 (Text-to-Image Loss)을 의미합니다. 이때 cross-entropy loss를 통해 계산 되며 정답 인덱스에 대한 예측 확률을 극대화 하는게 목적입니다.
\[L = \frac{L_i + L_t}{2}\]그리고 다음과 같이 최종 손실을 다 Loss의 평균으로 계산합니다. 이와 같은 symmetric loss를 사용해 양방향에서 일관적인 예측을 할 수 있게 됩니다.
2. Create dataset classifier from label text
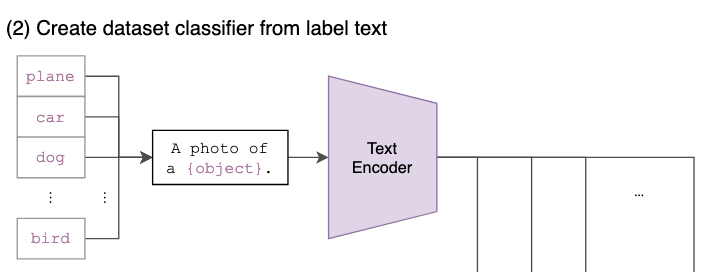
다음은 기존의 클래스 라벨에 대해 프롬프트 텍스트를 추가하는 단계입니다. 이때 프롬프트를 추가하는 이유는 사람은 이미지를 볼 때 다양한 방식으로 표현이 가능하기 때문에 모델이 더 많은 상황에 대응할 수 있는 임베딩을 학습하기 때문입니다. 즉 해당 방식을 통해 모델의 일반화 성능을 올릴 수 있고, 이게 zero-shot learning에 도움이 됩니다.
이는 예를들어 “dog”, “cat”, “plane”와 같은 클래스가 있을 때 “A photo of a {}.”, “An image of a {}.”, “A picture of a {}.” 다음과 같은 템플릿을 사용하여 “A photo of a dog.”와 같은 문장을 생성하게 됩니다. 해당 문장을 pre-training시킨 모델을 통해 임베딩 시킵니다.
3. Use for zero-shot prediction
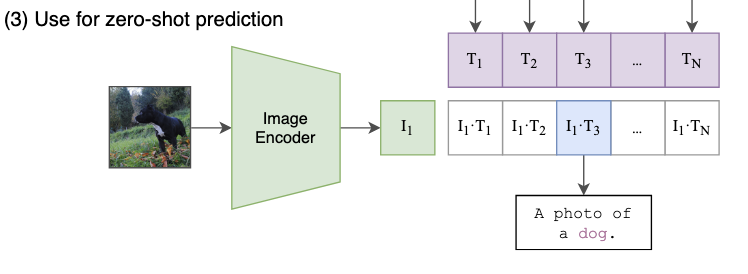
이제 해당 프레임워크에 zero-shot prediction을 할 수 있습니다. 새로 들어온 이미지에 대한 임베딩을 구하고 위의 문장들의 임베딩과 consine similarity를 계산합니다. 이때도 softmax를 통해 확률분포를 구하고, 가장 높은 유사도를 갖는 클래스를 생성하게 됩니다.
zero-shot의 경우 처음보는 이미지에 대한 예측이 가능하다는 점을 볼 수 있지만 그렇다 해서 새로운 문장을 만드는 것은 아니며, 이미 제공된 텍스트 중 가장 유사한 것을 선택하는 방식으로 예측을 진행하게 됩니다. 즉 모델 성능이 프롬프트의 질과 다양성에 따라 예측 성능이 달라진다는 한계가 있습니다.
Experiment
CLIP논문에서는 굉장히 다양한 실험을 진행하였습니다. 그중 일부 실험 결과만 가져왔습니다.
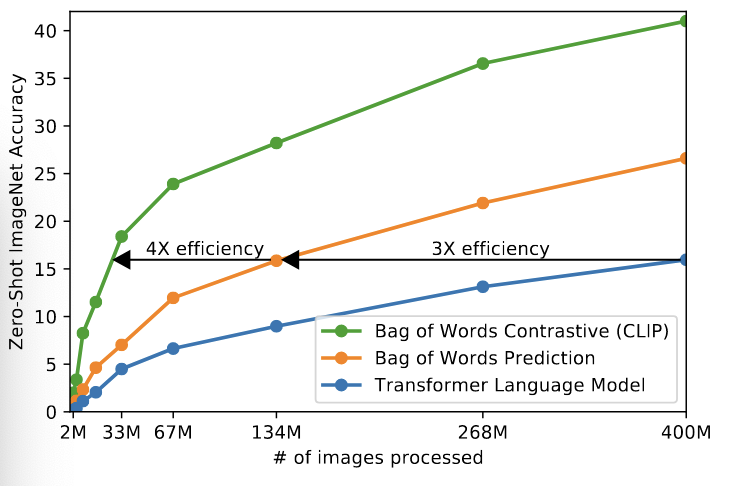
해당 실험에서 CLIP 모델이 다른 모델과 비교할 때 Zero-Shot ImageNet의 정확도를 비교합니다. 여기서 X는 학습에 사용된 이미지의 수, 그리고 Y축은 Zero-Shot ImageNet 정확도를 의미합니다. 여기서 CLIP은 다른 모델에 비해 약 4배 더 효율적인 zero-shot 성능을 보였습니다.
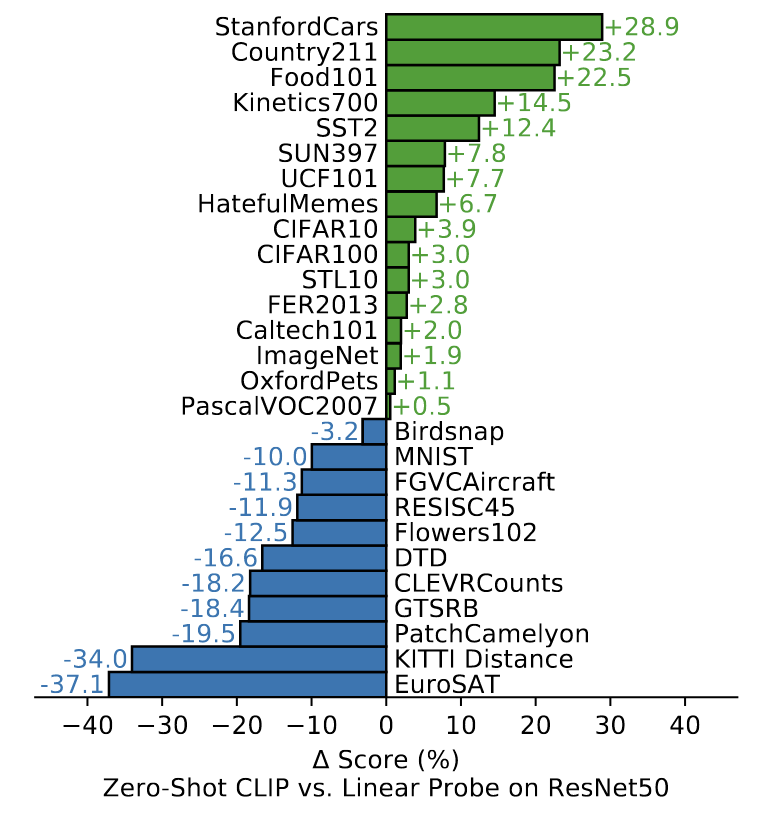
다음은 ResNet50 모델과 비교할 때 Linear Probe 성능을 비교한 것입니다. 초록색은 CLIP이 더 좋은 성능을 보인, 파란색은 ResNet50이 더 좋은 성능을 낸 데이터셋을 말합니다. 여기서 CLIP은 일반적인 이미지 분류나 다양한 환경에서 좋은 성능을 보였지만, 특수목적으로 만들어진 데이터셋에선 기존 모델보다 낮은 성능을 보일 수 있음을 시사합니다.
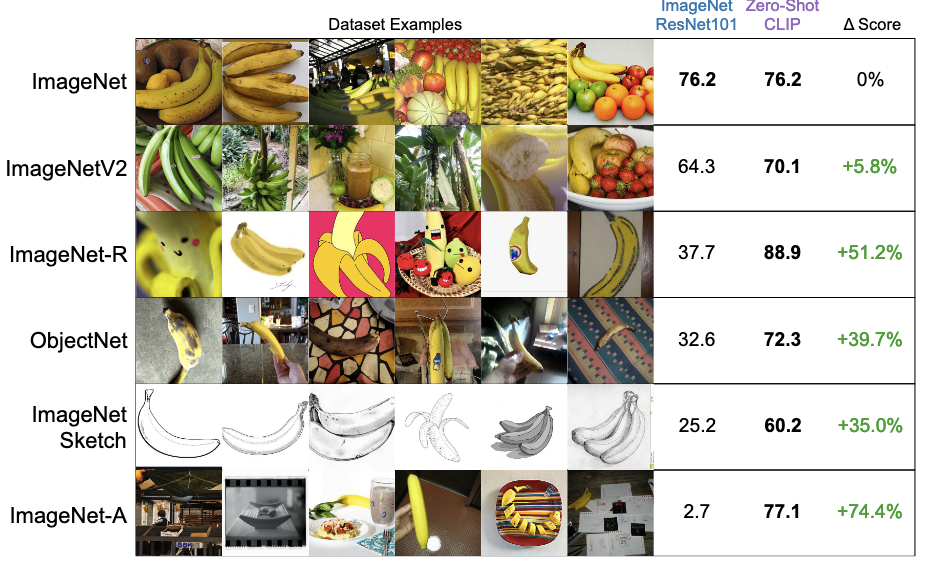
세번째로 다양한 데이터셋에서 CLIP의 Zero-shot 성능을 비교한 것입니다. 비교 대상은 ImageNet ResNet101이며, 일반적인 이미지넷에서는 둘다 비슷하게 좋은 정확도를 보이지만 다른 데이터셋에서는 CLIP이 훨씬 더 좋은 성능을 보이는 것을 볼 수 있습니다. 즉 여기서 CLIP의 zero-shot 능력이 강력하다는 것을 알 수 있습니다.