[논문리뷰 / ICLR 2015] VGGNet - Very Deep Convolutional Networks for large-scale image recognition
ICLR 2015. [Paper]
Karen Simonyan, Andrew Zisserman
Visual Geometry Group, Department of Engineering Science, University of Oxford
4 Sep 2014
이미지 넷 모델 리뷰
Introduction
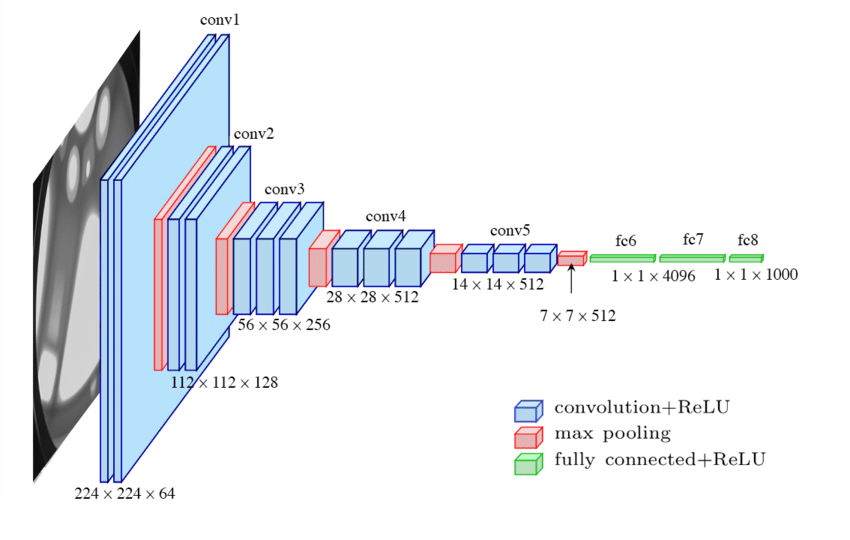
해당 논문은 2014년에 ILSVRC image classification 에서 준우승을 한 모델로서, 인공지능 발전에서 굉장히 중요한 평가를 받는 논문이다. 해당 논문에서는 alexnet과 같은 CNN 아키텍처에서 5x5 필터 대신 3x3 필터 만으로 아키텍처를 구성하여, 그 당시에는 매우 깊은 16-19층의 레이어를 쌓을 수 있었다. 해당 모델이 구글넷에 밀려 준우승을 차지하긴했지만, 구조가 단순하여 백본으로서는 더 사랑 받은 모델이다.
CONVNET CONFIGURATIONS
Architecture
모델의 특징을 정리하면 다음과 같다
- 전처리는 각각의 RGB 평균을 빼주는 것만 진행
- 모든 필터에 가장 작은 receptive field를 갖는 3x3 필터를 사용함
- 일부 실험에서는 입력채널을 변환해주는 1x1 Conv필터도 사용했다고 함.
- Stride는 1px
- 패딩은 input이 유지되도록 준다.
- Conv레이어 뒤에 2x2, stride는 2 Maxpooling 사용(총 5개)
- Conv레이어 뒤에는 FC 레이어
- 4096 $\rightarrow$ 1000 채널이되도록, 마지막 레이어는 softmax
- 모든 hidden layer 에는 ReLU를 non-linearity로 준다.
- AlexNet의 LRN(Local Response Normalisation)은 적용하지 않음
CONFIGURATIONS
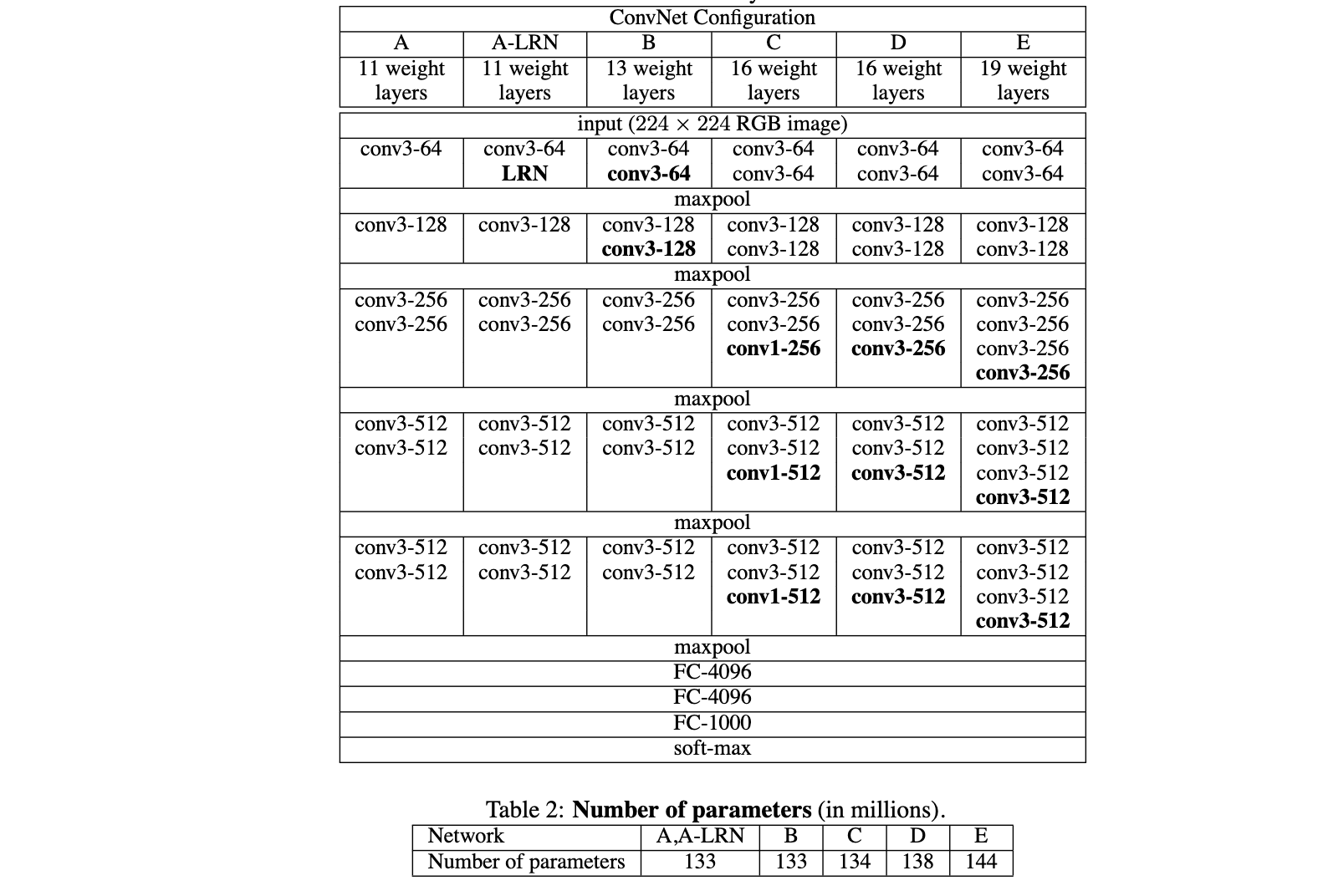
해당 논문에서는 위 아키텍처를 위 표와 같이 구성하였다. 하나의 Column이 하나의 모델 아키텍처를 의미한다. 모든 모델의 아키텍처 특징은 위에 기술한 바와 같고, LRN의 적용여부와 레이어 수에 차이가 있다. 점점 레이어를 지나면서 Conv Layer의 채널이 증가하는데 이를 논문에서는 conv layer의 width가 증가한다고 하고 있다. 그리고 테이블2에서는 각 모델 구성에 대한 파라미터 수를 기술하고 있다. 여기서 모델이 더 깊어짐에도 불구하고 필터수가 적고(layer width가 적고) receptive field가 적기(필터 크기가 3x3로 작기) 때문에 파라미터의 수가 크게 증가하지 않는다.
DISCUSSION
기존 ILSVRC 대회에서 우승한 모델들을 보면 큰 receptive field(11x11, 7x7 등)를 사용한다. 하지만 해당 논문에서는 모든 것을 3x3 receptive field를 사용한다. 이는 2개의 3x3 Conv를 사용하면 5x5의 receptive field와 동일한 효과를 낸다는 것을 알 수 있다. 마찬가지로 3개의 3x3 Conv layer는 7x7의 효과를 낸다.
그렇다면 큰 receptive field를 사용하는 것에 비해 작은 receptive field를 쌓으면 어떤 장점이 있을까? 첫번째로 non-linear rectification layer를 여러개 넣음으로서 판별력이 더 높아진다는 점이다. 즉 모델의 설명력이 증가한다고 볼 수 있다. 두번째로는 모델의 파라미터가 감소한다. 예를들어 7x7을 대체하기 위해 3x3을 3번쌓는다고하면 3x3은 3x3x3 = 27의 파라미터를 학습해야하지만, 7x7 은 49개의 파라미터를 학습해야한다. 즉 모델의 파라미터가 더 적게 제약이 걸리므로 7x7 Conv에 정규화가 적용됐다고 볼 수 있는 것이다.
Configuration C를 보면 1x1 Conv레이어가 적용되어있다. 이는 구글넷에서도 사용되는 것으로 Receptive field에 영향을 주지 않고 non-linearity를 증가시켜줄 수 있는 방법이다.
그 뒤로는 모델에 대한 자랑을 하는데 작은 필터를 적용시키는 연구는 있었지만 이렇게 깊게 쌓지 못했다느니, 구글넷이 2014년 대회에서 우승하긴 했지만 모델이 더 복잡하느니와 같은 내용이 나온다.
테스트 과정의 Image 처리
그다음으로 볼 것은 test과정에서의 이미지 처리 방법이다. 해당 기법들을 사용하여 모델을 구성하였다.
Image Rescaling VGGNet은 원본이미지를 정사각형 형태(Isotopic)로 Rescaling하여 Q의 형태로 변환한다. 이때 Q는 S(훈련 이미지)와 다른 크기 일 수 있다.
FC 레이어를 Conv 레이어로 변환 그 후에 일반적인 CNN 모델 끝에 FC레이어가 있는 것과 달리 마지막 레이어를 Conv레이어로 대체하여 완전한 Conv레이어 즉 Fully Convolutional Network (FCN) 의 형태로 변환한다. 이때 첫번째 FC레이어는 7x7 Conv로 나머지 2개는 1x1로 사용한다. 1x1을 사용하므로 마지막 채널이 클래스의 갯수와 같아지고 클래스들의 scoremap이 된다.
Dense Sliding window 적용 변환된 FCN을 원본이미지 전체에 슬라이드 윈도우 방식으로 적용한다. 그리고 각 위치에 대한 class score map을 만든다.
Spatial Average Pooling (Sum Pooling) 그 이후에 네트워크가 출력한 class score map에 대해 평균을 내어 하나의 벡터형태로 나타낸다. 즉 이미지 사이즈가 어떻게 되던 간에 클래스에 대한 확률 값을 얻을 수 있는 것이다.
해당 방식을 통해 multi-crop evaluation(이미지를 여러 크롭으로 분할하여 여러번의 CNN을 적용하는 방식)방식에 비해 빠르게 처리할 수 있다.그 뒤 평가 부분이나 구현에 대한 부분의 경우, 기존의 일반적인 사용방법이거나 caffe와 같은 과거의 딥러닝 프레임워크를 사용했기에 생략하도록 하겠다.
VGG 모델 코드 설명
class VGG(nn.Module):
def __init__(
self, features: nn.Module, num_classes: int = 1000, init_weights: bool = True, dropout: float = 0.5
) -> None:
super().__init__()
_log_api_usage_once(self)
self.features = features
self.avgpool = nn.AdaptiveAvgPool2d((7, 7))
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(True),
nn.Dropout(p=dropout),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(p=dropout),
nn.Linear(4096, num_classes),
)
if init_weights:
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode="fan_out", nonlinearity="relu")
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
해당 코드는 alexnet과 마찬가지로 torchvision에서 구현된 코드이다. alexnet과 마찬가지로 보기에 엄청나게 어려운 코드는 아니다. 전체적인 구조가 alexnet과 거의 비슷하게 구성되어 있는데, forward 부분만 보면 완벽하게 유사하다. 실제 파이토치의 모델이 어떻게 동작하는지 보기위해 전체 코드를 꼼꼼하게 보도록하자.
if init_weights:
for m in self.modules(): # 모델의 모든 모듈(layer)을 순회
if isinstance(m, nn.Conv2d): # Convolutional Layer일 경우
nn.init.kaiming_normal_(m.weight, mode="fan_out", nonlinearity="relu") # Kaiming 초기화 적용
if m.bias is not None:
nn.init.constant_(m.bias, 0) # Bias를 0으로 초기화
elif isinstance(m, nn.BatchNorm2d): # Batch Normalization Layer일 경우
nn.init.constant_(m.weight, 1) # Scale 파라미터를 1로 초기화
nn.init.constant_(m.bias, 0) # Bias를 0으로 초기화
elif isinstance(m, nn.Linear): # Fully Connected Layer일 경우
nn.init.normal_(m.weight, 0, 0.01) # 평균 0, 표준편차 0.01의 정규분포에서 초기화
nn.init.constant_(m.bias, 0) # Bias를 0으로 초기화
우선 alex에는 없는 가중치 초기화 부분이 존재한다.(__init__내부의 if문) 해당 부분에는 만약 옵션으로 가중치 초기화를 줄 경우(기본값이 True) 가중치 초기화를 진행한다.
우선 첫 반복문을 보면 모든 레이어를 순회하게 된다. 이는 nn.Module에 있는 modules메소드가 포함하고 있는 서브모듈을 iterable(반복문으로 순회할 수 있는)형태로 반환해준다. 따라서 해당 모듈을 순회하며, 해당 모듈이 어떤 모듈인지에 따라 다르게 초기화를 진행해주는 것이다.
초기화하는 방법은 nn.itit에 있는 메소드를 이용하여 초기화를 진행한다. 우선 여기서 눈여겨봐야할 점은 bias의 경우 모두 0으로 초기화를 해주지만, weight의 경우 모두 다르게 초기화를 해주고 있다는 점이다.
가중치 초기화 방법
- Conv2d : 여기서 카이밍(kaiming) 초기화 방법을 사용해주고 있다. 이는 입력한 레이어 노드의 수에 따라 다르게 초기화해주는 방법인데 주로 ReLU와 함께 자주 사용한다.
- BatchNorm2d : 여기서 상수 1로 초기화 하고 있다. 배치정규화는 입력데이터를 정규화하여 학습이 안정적으로 진행할 수 있게 한다. 이때 배치정규화가 초기 학습에 큰 영향을 주지 않게 하기 위해서 다음과 같은 값을 할당한 것이고 학습이 진행됨에 따라 해당 값이 적절한 값으로 변경될 것이다.
- Linear : FC레이어는 정규분포로 초기화를 해주는데 이때의 값은 평균이 0이고 표준편차를 굉장히 작은 값을 주어 0에 굉장히 가까운 값이 할당되게 하였다. 0으로 초기화할 수 있는데 왜 이렇게 정규분포로 초기화했는지 의문을 가질 수 있다. 이는 모든 뉴런이 0으로 업데이트 되어 symmetry problem으로 학습이 잘 진행되지 않을 수 있기 때문에 0에 근사한 정규분포의 값으로 값을 할당하는 것이다.
def make_layers(cfg: List[Union[str, int]], batch_norm: bool = False) -> nn.Sequential:
layers: List[nn.Module] = []
in_channels = 3
for v in cfg:
if v == "M":
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
v = cast(int, v)
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
return nn.Sequential(*layers)
모델 정의 부분을 보면 전체적으로 alexnet과 큰 차이를 보이지 않는다. 이때 alexnet과 큰 차이를 보이는 부분은 CNN 부분이다. 모델 정의 부분에서 Conv2d 레이어를 쌓는 부분이 존재하지 않는다. 이는 feature를 생성하는 모듈을 통해 레이어가 만들어진다.
해당 make_layers는 이미지로부터 feature를 추출하는 레이어를 만드는 모듈이다. 해당 함수는 nn.Sequential로 되어있는데 이는 nn.Module의 일부이기 때문에 위의 모델 정의 부분에서 feature의 옵션으로 받게된다. 해당 함수는 인자로 cfg를 받는데 이는 어떤 버전의 VGG모델을 선택할지를 넣어주어야한다. 해당 cfg의 경우 아래와 같은 형식으로 존재한다.
cfgs: Dict[str, List[Union[str, int]]] = {
"A": [64, "M", 128, "M", 256, 256, "M", 512, 512, "M", 512, 512, "M"],
"B": [64, 64, "M", 128, 128, "M", 256, 256, "M", 512, 512, "M", 512, 512, "M"],
"D": [64, 64, "M", 128, 128, "M", 256, 256, 256, "M", 512, 512, 512, "M", 512, 512, 512, "M"],
"E": [64, 64, "M", 128, 128, "M", 256, 256, 256, 256, "M", 512, 512, 512, 512, "M", 512, 512, 512, 512, "M"],
}
이게 cfg 딕셔너리이며, 정확히는 모델의 구조를 정의한 딕셔너리이다. 해당 딕셔너리에는 총 4가지의 VGG 버전의 형태가 저장되어 있다.
- A : VGG-11
- B : VGG-13
- D : VGG-16
- E : VGG-19
여기서 cfgs안에 정의된 숫자의 경우 Conv2d에서 만들 feature map의 채널 수 이며, M은 Maxpooling레이어가 나올 차례임을 보여준다.
자 이제 make_layer함수를 준비가 되었다. 해당 함수에서는 layers에 구성할 레이어를 저장한다. 그 이후 in_channels의 경우 입력 채널을 정해주게 된다. 입력 채널은 레이어를 쌓을때마다 업데이트한다. 만약 문자 M이 들어온다면 Maxpooling레이어를 추가해주고, 그렇지 않다면 Conv레이어를 숫자만큼 넣어주게된다. cast는 숫자를 int형으로 타입캐스팅 해주는 함수이다. 만약 batch nomalization을 하는걸 옵션으로 넣었다면 추가적으로 batch nomalization 레이어를 추가해준다. 그리고 마지막에는 이렇게 만든 리스트에 nn.Sequential를 감싸서 반환해준다.
def _vgg(cfg: str, batch_norm: bool, weights: Optional[WeightsEnum], progress: bool, **kwargs: Any) -> VGG:
if weights is not None:
kwargs["init_weights"] = False
if weights.meta["categories"] is not None:
_ovewrite_named_param(kwargs, "num_classes", len(weights.meta["categories"]))
model = VGG(make_layers(cfgs[cfg], batch_norm=batch_norm), **kwargs)
if weights is not None:
model.load_state_dict(weights.get_state_dict(progress=progress, check_hash=True))
return model
이제 실제 모델의 구조가 어떻게 만들어졌는지까지는 모두 이해했다. 이제 해당 모델의 인스턴스를 만들어주는 _vgg함수이다. 해당 함수에서는 인자를 받아서 실제 인스턴스를 만들어주는 함수이다. 해당 함수에서는 weight가 있는 경우에는 weight 초기화를 진행하지 않고, weight를 불러와 모델에 로드해주는 함수이다.
@register_model()
@handle_legacy_interface(weights=("pretrained", VGG11_Weights.IMAGENET1K_V1))
def vgg11(*, weights: Optional[VGG11_Weights] = None, progress: bool = True, **kwargs: Any) -> VGG:
weights = VGG11_Weights.verify(weights)
return _vgg("A", False, weights, progress, **kwargs)
이제 실제로 vgg 모델을 만들고 생성해주는 함수이다. 해당함수에서 weight가 들어온다면 weight가 해당 함수에 맞는 weight인지 여부를 검증하고, 만약 들어오지 않는 다면 VGG11_Weights의 파이토치 사이트에서 모델을 pth형식으로 받아 불러오게 된다.
import torch
import torchvision.models as models
model = models.vgg11(weights=models.VGG11_Weights.IMAGENET1K_V1)
model.eval()
이와 같은 방식으로 vgg-11 모델을 불러온 후
url = "이미지 링크"
image = Image.open(requests.get(url, stream=True).raw)
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), # 정규화
])
input_tensor = preprocess(image)
input_batch = input_tensor.unsqueeze(0)
output = model(input_batch)
다음과 같은 방식으로 모델을 사용해볼 수 있다.